2021-12-20
Day 2 of fastai class.
The problem with p-values🔗
Ways of determining whether a relationship would happen by chance?
Independent variables Dependent variables
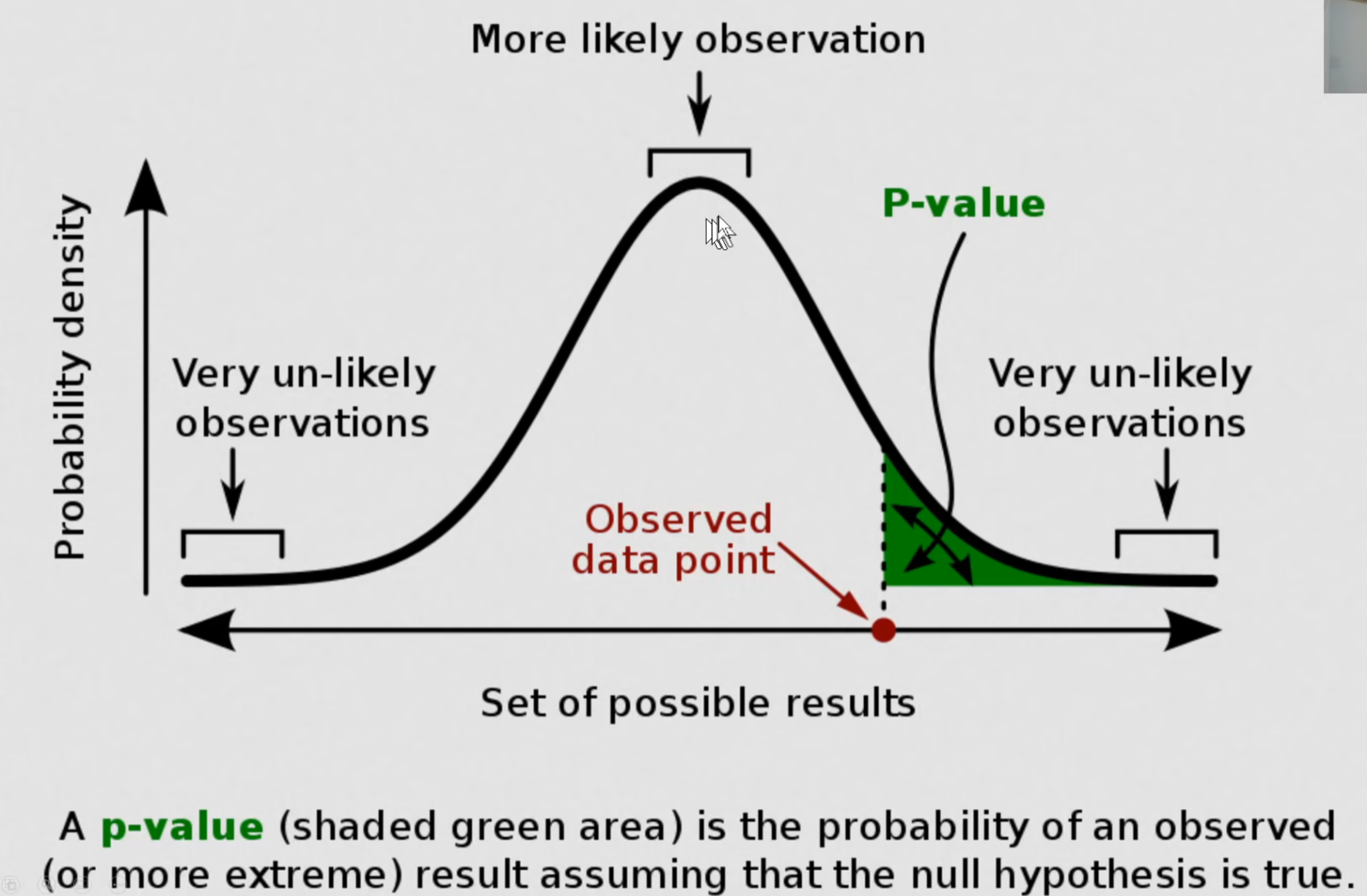
One way of doing this is by simulation.
Another way to do this is by looking at the p-value, i.e., the probability
of an observed or more extreme result assuming that the null hypothesis is
true. See wikipedia article on
p-value
Unfortunately, p-values are not useful - bottom line is that it doesn't say anything about the importance of a result.

See Frank Harrell's work.
p-values are a part of machine learning.
The outcome that we want from our models is whether they predict a practical result or outcome. In Jeremy's critique of the temperature-R relationship paper, he's
Another way to look at this set of problems is through the lens of outcomes that you want from your model. He has a 4 step process. In the example, he's looking at the objective of maximizing the 5 year profits of a hypothetical insurance company. Next he looks at the levers, i.e., what can you control which in the case of insurance it's the price of a policy for an individual. Next he looks at the data that can be collected, i.e., the revenues and claims and the impact those have on the profitability. He then ties the first thee things: objective, levers, and data together in a model which learn how the levers influence the objective. This is all discussed in this article that he wrote in 2012
"Using data to produce actionable outcomes", i.e., don't just make a model to predict crashes, instead have the model optimize the profit.
Deploying the bear detector (black, grizzly, teddy) reminds me of Streamlit. It might be a really interesting exercise to build the bear model from the class and deploy it as a local streamlit app (and perhaps think about what it would take to deploy it to Azure as well).
A great tribute by Steven Sinofsky to the Apple Bicycle for the Mind. It would be great to create a modern poster for this someday.
