2021-12-27
This is the best explainer of how Airline frequent flyer programs really work. Airlines are effectively sovereign currency issuers with the caveat that not only do they control issuing currency, they also control the only means by which the currency can be redeemed. While this is not entirely true, i.e., you can purchase goods and services by redeeming frequent flyer miles, you'd have to be crazy to do so given the terrible exchange rates that are offered by the credit card issuers.
This diagram does a great job at explaining how Wall Street values airlines and their frequent flyer programs. Effectively operating an airline is a loss- leader for providing frequent flyer miles! Now, there's an arbitrary multiplier applied over EBITDA to come up with the valuation of the frequent flyer programs but this is still a stunning figure:
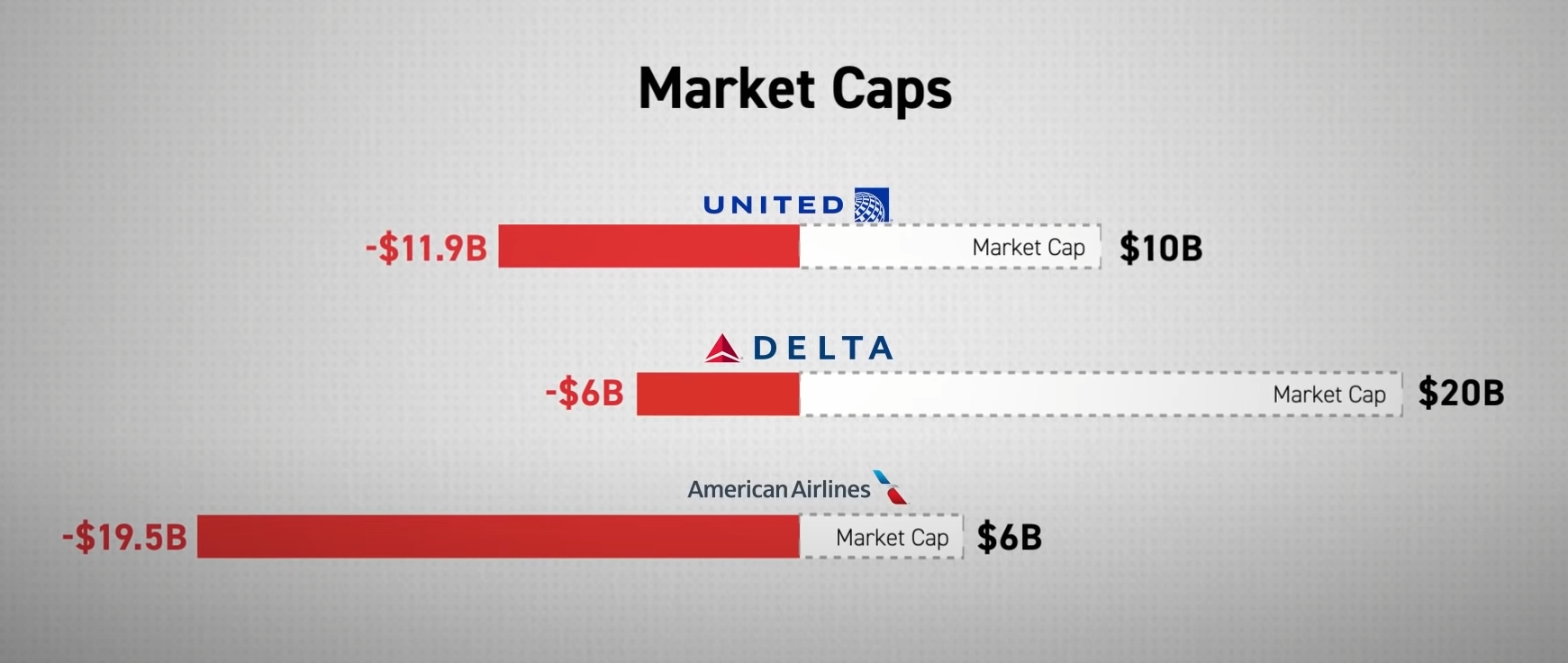
The video also does a great job at explaining how different forms of arbitrage have been systematically eliminated by the airlines. For example, mile arbitrage (i.e., find a cheap flight that went on a circuitious route that would yield a large number of miles for a low cost) have been eliminated by pegging reward miles to the dollar spend vs. the miles flown. They also do the same thing on the redemption side as well. I used to run an arbitrage on this many years ago when I could fly anywhere at anytime for 25K miles. I would charge customers for the flight at a discount over the current flight cost, e.g., if a flight cost $1200, I would sell for $1000 and redeem 25K miles for $1000 for an unheard-of $.04 per mile. Yes, I would get taxed on the income for that flight but that was still an unheard-of redemption rate for miles.
One of the challenges of building a semantic search engine is splitting the
input text into smaller chunks that are suitable for generating embeddings
using Transformer models. This
thread on the
Huggingface forums does a good job at breaking down the problem into smaller
pieces. The key insight from lewfun is using a sliding window algorithm over
the text in the document. For those who don't know, there is a limit on the
number of tokens (roughly words) that can be fed to a model. By using a
sliding window algorithm, you block the entire document and can map each block
back to the same original document. This way, you can use similarity based
models to generate a ranked list that maps back to the original document. This
will be the way that I will build the first version of my semantic search
engine.